
Learn Agentic AI: A Beginner’s Guide to RAG, MCPs, and AI Agents
Demystifying Agentic AI buzzwords — by a YC founder, for techies and non-te

Why this guide?
🛸 Agentic AI comes with a new dictionary of buzzwords: RAG, embeddings, tools, MCPs, prompting, pre-prompting, fine-tuning…
What are they? What do they do? Nobody really knows. 👾
When I first started diving into agentic AI, I realized I was pretending to know what half the words meant.
💡 This post is my attempt to demystify them — in a simple way — based on what I’ve learned building nao Labs (YC X25), our Cursor for data teams.
The hidden dictionary of AI agents
Agentic AI comes with a new vocabulary:
Prompting (system prompts, user rules, context files…)
Tools (functions an agent can call)
MCPs (collections of functions)
RAG (retrieval-augmented generation for context)
Embeddings & chunking
Fine-tuning & training
Here is how they all interact together:
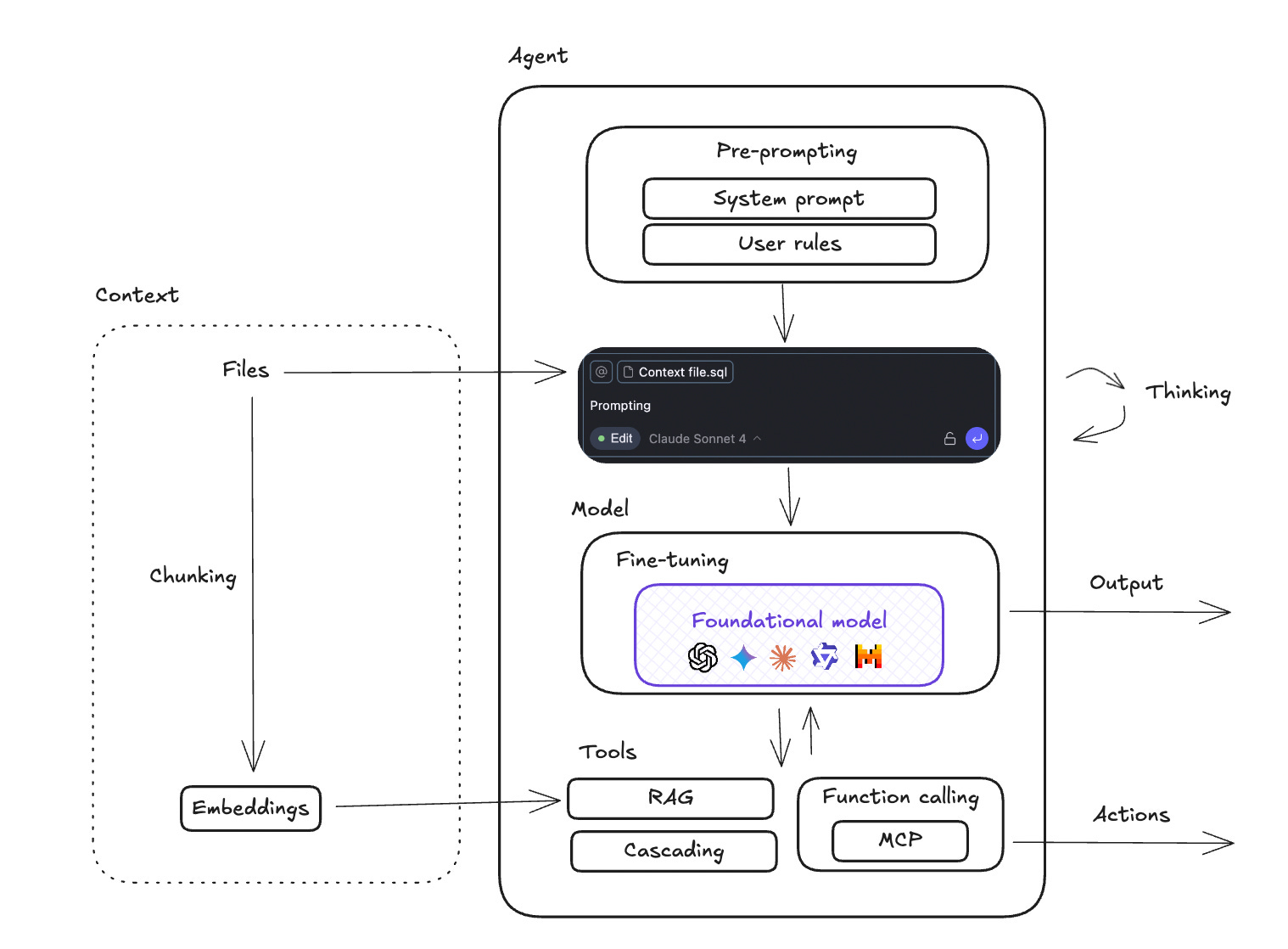
Here is what happens when you send a prompt to an AI agent 🧩
Pre-prompting
When you send your prompt, it is sent with the attached system prompt (general rules) and any user rules you’ve defined (like constraints or preferences). This sets the “personality” and specific rules of the agent.Context injection
If you added files to your prompt, those are added in the prompt text as well.The model
Your actual request, plus system instructions and context, are sent to a foundational model (GPT, Claude, Mistral, etc.).
Sometimes this model has been fine-tuned — adapted on specific data to perform better on your use case.Tools
In order to perform actions - and not only write text - the agent uses function calling. It calls tools - that actually are just code functions - which can do anything: create/modify a file, send emails, etc.
These tools can be brought by an MCP - which is a set of tools on a specific topic (ex: a gmail MCP will bring tools like write email / read email)RAG
Your whole accessible context can be too big to send entirely to your prompt. RAG is used to retrieve the right piece of context to send to the agent. In order to use RAG, you need to create embeddings of your files: chunk them in pieces and then create embeddings that can be searched by your RAG.
1. Pre-prompting 💬
When you ask the agent “I want to modify this file”, there’s actually a lot of context and tools given to the agent to perform this task.
The agent receives a full prompt with:
System prompt: general instructions for the agent
Tools list: all available functions to act programmatically (and how to use them)
User rules: rules specified by the user (think your .naorules file)
Context files: content of files attached
User prompt

This is why the quality of agents varies so much — a big part of their instructions is the system prompt and their tools. Actually, studies have shown that tools can reduce agent error rates by 5 to 10 times.
2. Function calling 🦾
LLMs are only capable of generating text.
So how can they actually perform actions like creating files, sending emails, or executing code?
👉 The key is in their tools.
As a user, you might sometimes see tool call boxes appear in the chat.
From the agent's perspective, this is called function calling.
There are 4 steps to function calling:

LLM is given a list of functions
When prompted, the LLM is provided with the functions it has access to.
For example, a function like "list_files" with an argument "folder".LLM calls a function
During the conversation, the LLM generates a json text that specifies the function to call and the parameters.Function is executed
That function is then executed programmatically and returns a result.Output is passed back to the LLM
The result is given to the LLM, which can then use it to generate a final response for the user.
3. MCPs 🛠
A few months ago, the AI community started calling MCPs the next big revolution. But the real game-changer is function calling — MCPs are simply libraries of functions.
An important thing to understand is:
⚠️ MCPs don't bring context to your AI agent.
🛠 They bring tools to your agent.
📊 Let's take this example: you want to query your BigQuery data with an AI agent.
You install a BigQuery MCP.
You ask a question about your data.
The agent still has no context on your data — so it triggers one of the MCP tools, like execute_sql, to answer your question.

💡 You can compare MCPs to a package of functions.
In Python, you import packages that contain functions.
In your agent, you import MCPs that provide new functions.
So, an MCP is only as powerful as the functions it contains.
That’s why at nao, we decided to integrate natively with the data warehouse — to bring context on your data to the agent, beyond just function calls.
I talk a lot about this in my previous article ⬇️

4. RAG 🎣
Let’s keep up demystifying scary AI words: RAG, embeddings, chunking.
RAG answers a simple issue with LLMs: ingesting a large amount of context.
Let’s say you have a huge codebase, and you want your AI agent to change a piece of it. You can’t just send the whole codebase in context. First, that would be way too costly. Second, the LLM would be lost in the amount of context.
That’s why RAG was built: RAG allows you to retrieve only the piece of context that your LLM needs.
How does it work?

First, you need to create embeddings of your context files:
🧱 Files are all chunked into small bits (”chunking” step)
🧮 An embedding is created for each chunk – just a vector really (”embedding” step)
Then, when you prompt your agent, it calls RAG to retrieve the right context file:
📍RAG function computes the distance between your prompt vector and the embedding vectors
🎣 It retrieves the chunk of file with the closest distance, and gives it to your agent context.
That’s how you can find the relevant file among your 1000+ files codebase.
At nao, for example, we use RAG so that our AI agent can find the right table / column to use on a data warehouse of 20K+ tables.
5. Fine-tuning & training 🔮
Last but not least: what’s the difference between fine-tuning and training?
When people say “training a model”, they often mean very different things. There’s a big difference between training a model from scratch and fine-tuning an existing one.
To put is simply:
Training is creating foundational models
Fine-tuning is slightly re-training a foundational model
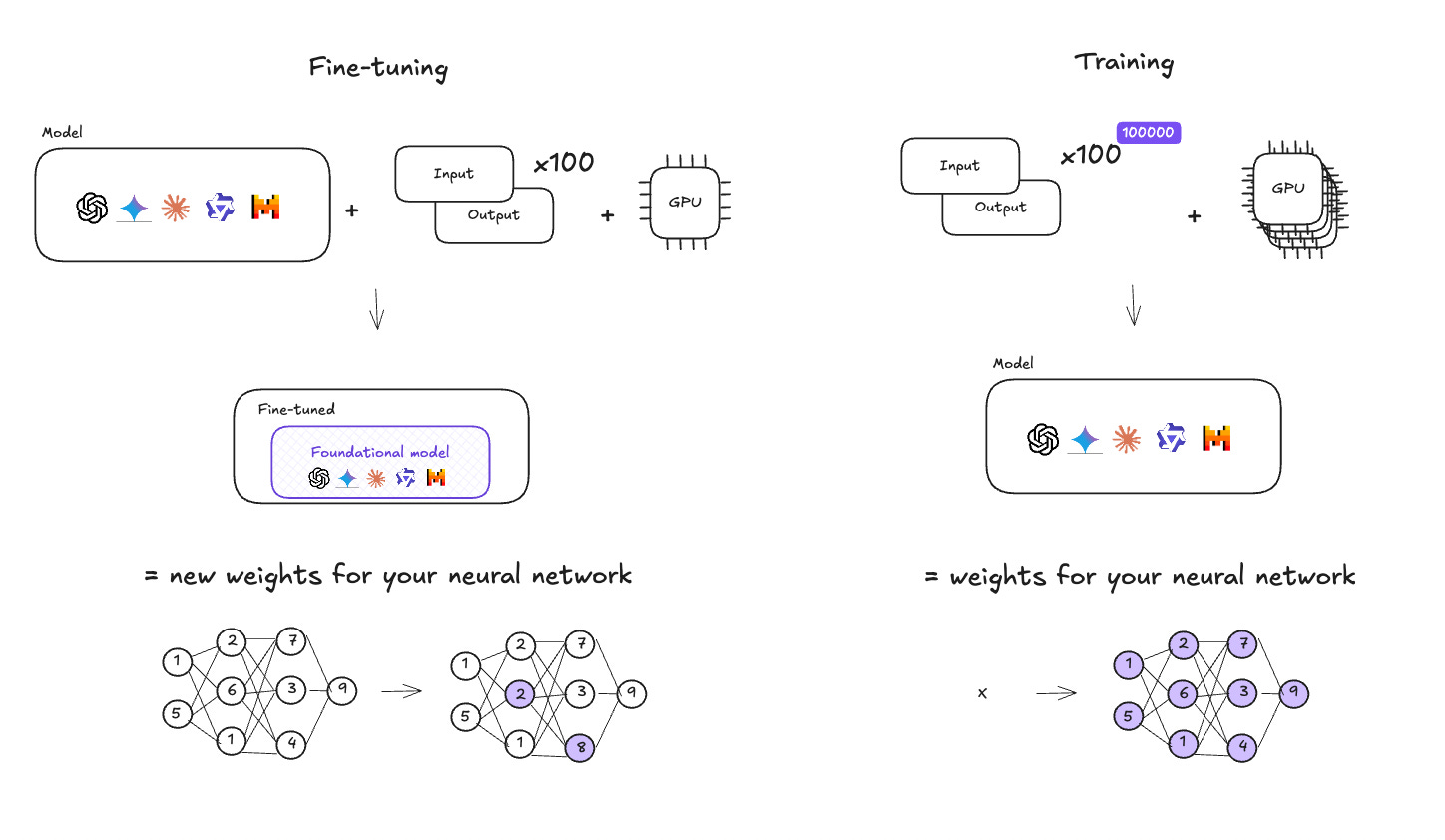
🏃🏻♀️ Training a model
Training a model starts with a huge amount of data, so that the model can have enough knowledge to answer any use case. It also requires a lot of computing power (GPUs) to process all this data.
The output is a foundational model, with defined neural network weights.
👩🏻🎨 Fine-tuning a model
Fine-tuning a model starts with an existing foundational model. Then the model is fed with another dataset (inputs/outputs, see details below), which results in modifying slightly the weights of the neural network.
The output is a new trained model, with new neural network weights.
In both cases, we use data to train and fine-tune the models.
What do we mean by “data”? A dataset of input / outputs.
For exemple, let’s say you want to fine-tune a model to do text to SQL. Your dataset will look like this:
Input: text of query to write 🗒
Output: SQL query 🖥”
In fine-tuning, you can start with just tens of samples, but in training, you need millions.
As you can see here, training model is not for everyone: it requires to have access to a lot of data, and costs a lot in terms of computing power. That’s why only a few companies actually train models to create foundational ones.
Usually, what “regular” companies do is rather fine-tune models on a specific use-case, with a limited size dataset (10-100 samples).
Final thoughts
Agentic AI isn’t magic. It’s a collection of well-designed components: prompts, tools, MCPs, and RAG — glued together to let LLMs do more than generate text.
The exciting part? We’re only at the beginning. Just like early programming languages, we’re still inventing the right abstractions.
At nao Labs, we’re exploring what this means for data teams: bringing both tools and context, so your agent doesn’t just generate SQL — it actually helps you get insights.
Let me know if this article has helped, and what you would want to learn more on!