
Why Cursor doesn’t work for data teams
And how to make it really work

Every developer has adopted their AI coding tool, first Cursor, then Claude Code.
These tools seem appealing for data teams as well, but in reality, they don’t match data team workflows.
I’m Claire, co-founder of nao Labs. I used to be Head of Data and now I am building nao, Cursor for data teams.
In this article, I’ll give you 3 reasons why Cursor doesn’t work for data teams. And show you 3 nao vs Cursor crash tests to prove it.
1️⃣ Cursor lacks half of the context: data
Writing code is 1D: your code context is self-sufficient. Everything is created by code, and the input and output are code.
Writing code on data is 2D: your input is data, your output is data. The code must match the data underneath, and output the right quality of data.
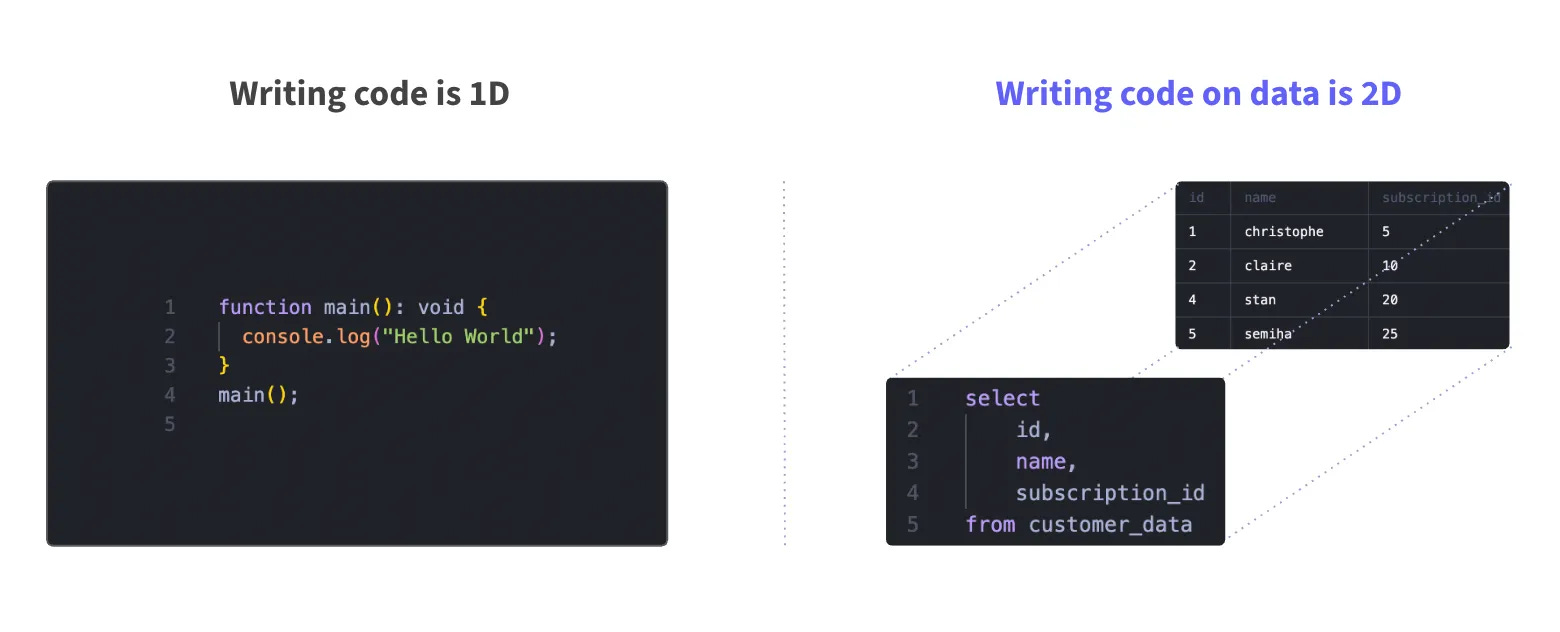
The issue with Cursor is: it only has the code context.
Which means: it hallucinates tables, columns, data types of your data.
The code is supposed to work but since it doesn’t match the input or expected output, it’s not working.
2️⃣ MCPs are an insufficient patch
MCP is the best solution today to patch against the lack of data context.
Here are 4 issues with MCPs:
Once again, data teams have to assemble their setup.
We already have to patch code editors with extensions (to access the data from the editor, work with dbt, etc.).
Data teams already know that it’s a pain - setting up a developer environment for his/her team is a data engineer nightmare. MCPs are not so easy to setup, and it becomes harder to maintain a consistent developer experience throughout the data team from data engineers to data analysts.
On top of that, there aren’t many official MCPs for data tools — so the risk is for your team to use different MCPs, and even some that might not be secure.
MCPs give tools, not context
MCPs are just a package of functions for function calling. This means they don’t bring any context to your agent directly - just tools to go look for this context.
Let’s say you want to run analytics on your data, so you ask a question to Cursor agent. It has no context on your data so it’s going to launch a series of tool calls to discover the data: list all datasets, then score which one is the most relevant, then get the schema of each table, then execute query. That’s a lot of tool calls to get such a core piece of context.
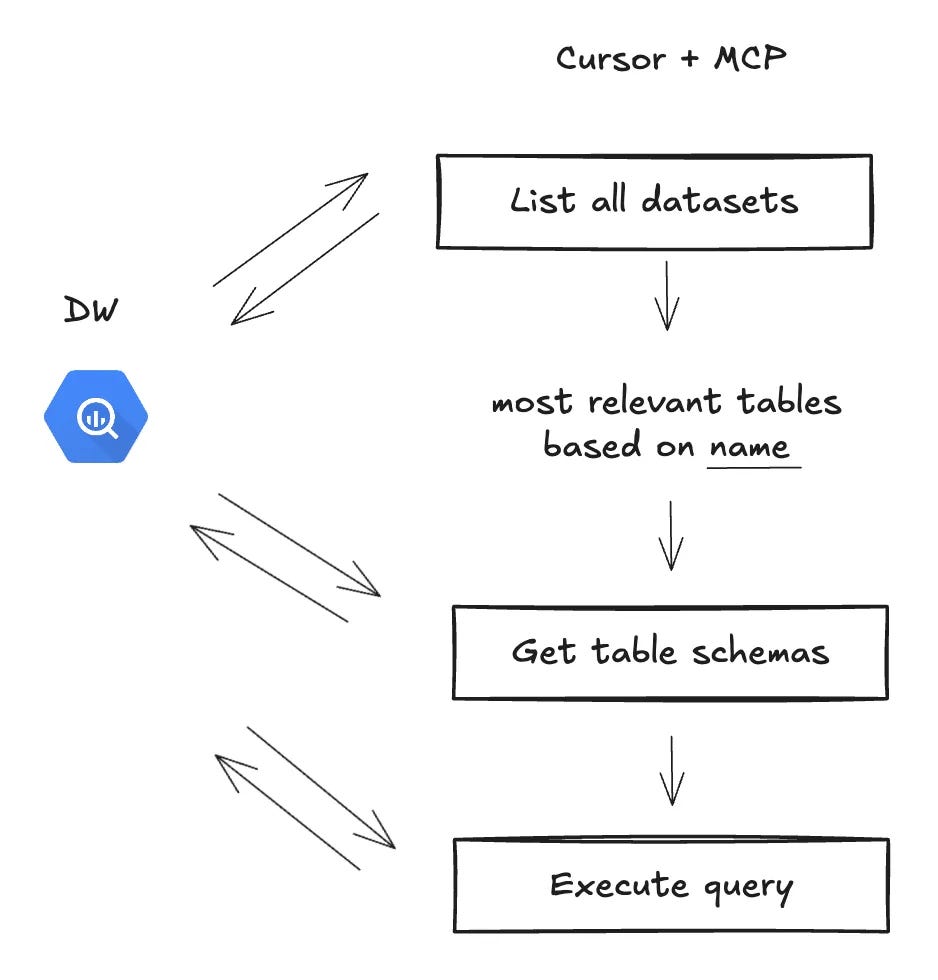
MCP is only accessible to the agent
MCP is a series of tools for the agent. It means only the agent has access to it. So the AI tab auto-complete for exemple still has no context on the available data. While you write, it’s going to hallucinate on available tables, columns, data types, and dbt models.
MCPs are not UI friendly for data
MCP helps query your data, but it doesn’t show you clearly the code it writes or the data it outputs. It’s very hard to sanity check what they do. And their output can’t be used to visualize data, trends, or share it with business stakeholders directly.

3️⃣ Cursor outputs code, not data
The key question you want to answer when doing code change as a data person is: What’s the data output?
You actually don’t care so much about the code itself but about the data output.
Cursor checks that the code is correct, might run it on the warehouse. But it has no notion of:
Data quality checks
Data regression testing
Data consistency checks (metrics consistency, lineage dependencies)
Data model optimization (factorization of code, optimization of query costs)
🔥 Why nao works
At nao we believe in
Integrating natively with your data stack tools
Data context flows everywhere from your AI tab to AI agent
UI is adapted to put data at core (data diffs, charts, tables in agent)
Pre-packaged setup for everyone
Native data warehouse access
nao is directly connected to your data warehouse and has access to your data schema, and uses a RAG on your data schema. This means: when you ask an analytics to nao agent, it calls the RAG to get the most relevant table, has its schema, and can start querying it right away.
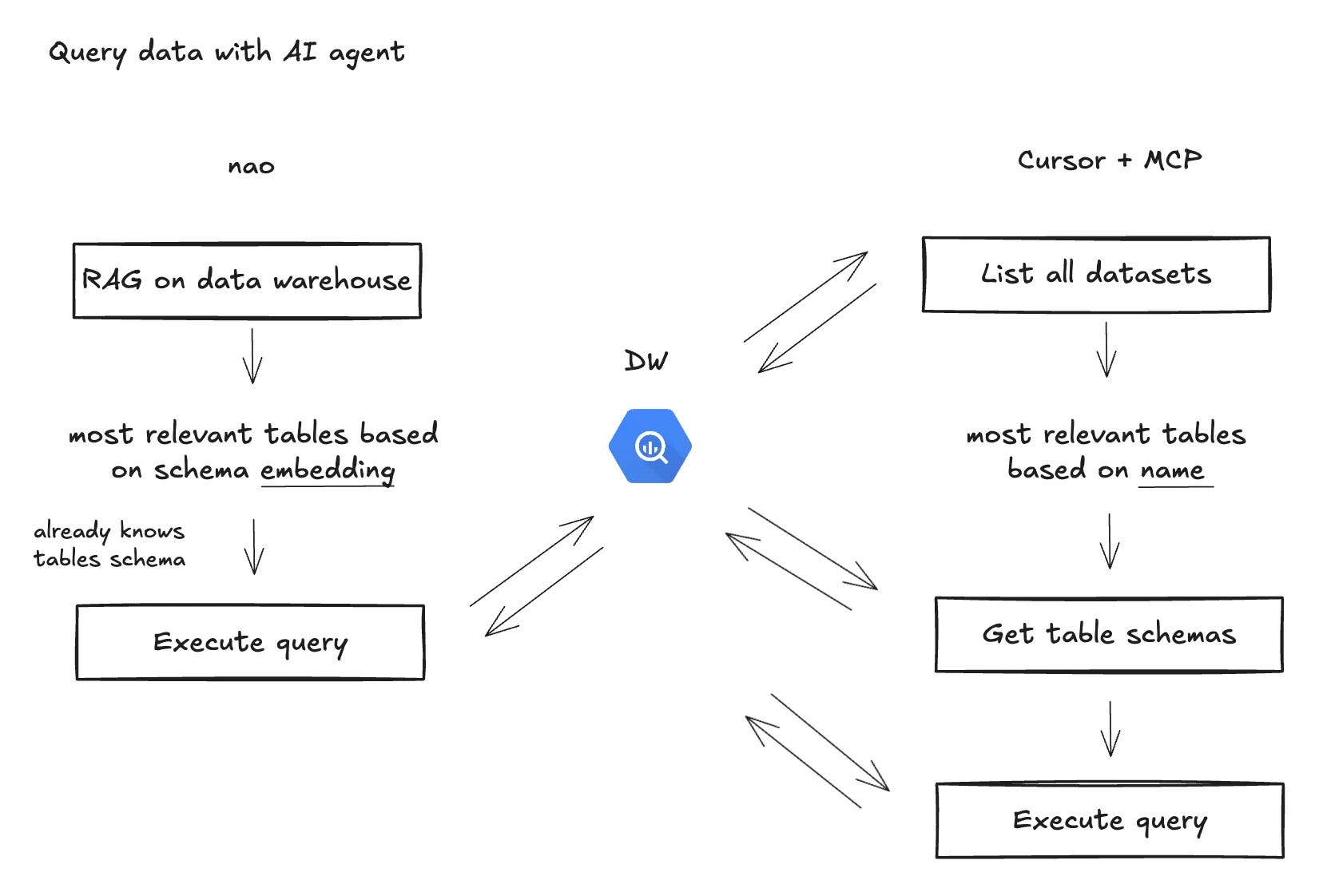
Data context is everywhere
The data context is sent to all AI features of nao, including the AI tab. It means that when you write code on your data, AI is going to autocomplete with actual tables, columns, and dbt models available.

UI for data changes, not code changes
nao focuses on showing you instantly the impact of your code on data: what was added, deleted, broken? Did your table granularity change? Did the distribution of a column change? All this in a glance with direct data diff.
Easy set-up
MCPs are hard to set up - from the chat, from the CLI. Lots of authentication and re-authentification issues. We know this is enough to discourage members of your team from using it. nao is just a simple form.

🎬 Cursor vs nao crash tests
We tried 3 data use cases where we compared:
nao on one side
Cursor + dbt MCP on the other side
Create a data model
Investigate a data quality issue
Run analytics
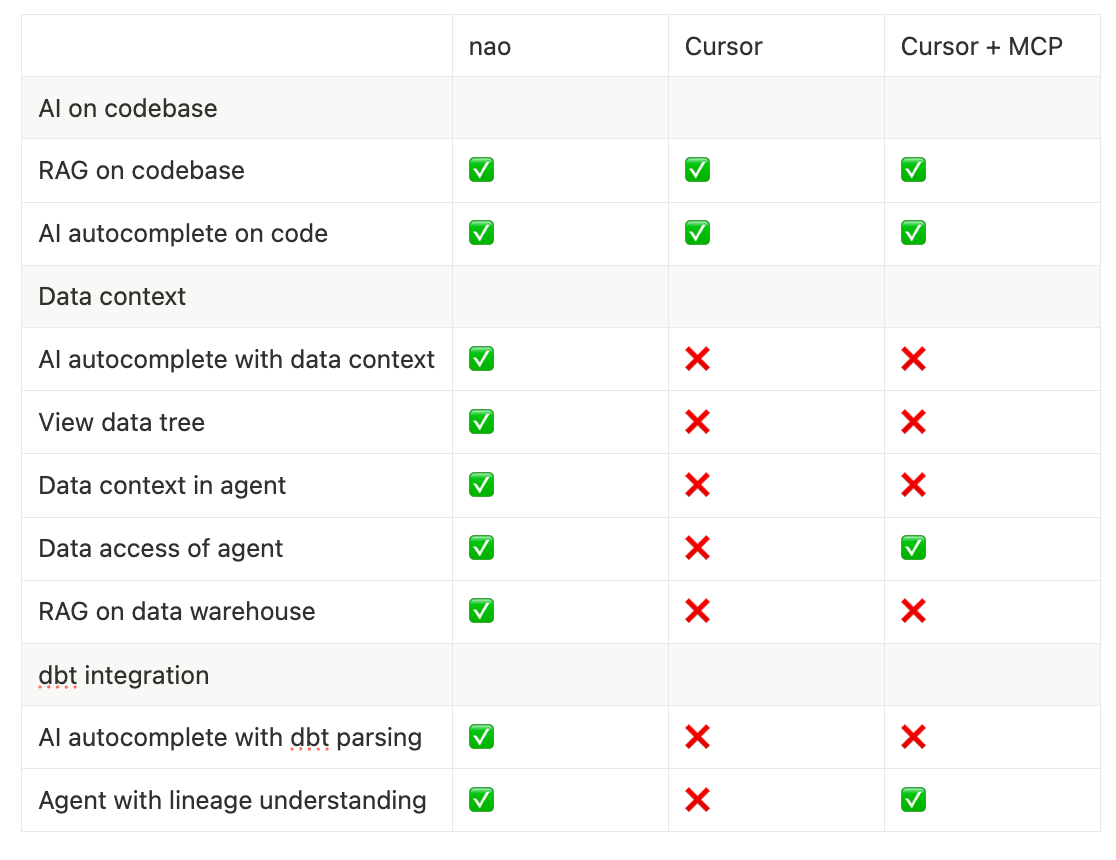
💡To sum it up
Here is a small recap on why nao checks all the boxes for data teams:
Let me know what you think and what you expect of our “Cursor for data”.
I spent a lot of time adding csvs to Cursor for extra content on input and few shot examples to make it work, but even with that I still end up doing manual checks. Will give nao a shot!
Oh god, how much do I identify with this post. I like the 1D vs 2D definition.
Ive had so many engineers approach me and say “well, isn’t ML just code? I can now do that with ChatGPT!”