
How to code an AI agent - text to SQL edition
Step-by-step Python code to create your own AI agent with pre-prompting, context and tools

In our last article “Learn Agentic AI: A Beginner’s Guide”, we demystified the core components of an agent. Now it’s time to get to the real challenge: applying these learnings to writing the actual code.
I wrote a simple 200-line script to build an analytics agent.
This is a basic agent for now - with pre-prompting, context text, and one tool. The goal is to show how the core concepts translate into code and how they orchestrate together.
💡 This post is my attempt to help you build your own AI agents — based on what I’ve learned building nao Labs (YC X25), our Cursor for data teams.
Feel free to take this code and build on it!
🎯 Our AI agent goal
The goal here is to build an AI analytics agent that will:
Receive analytics request from the user
Use OpenAI’s GPT-5 to write SQL
Query data available in BigQuery with tools
Have the agent comment on the result - or not if in privacy mode !
I’ve taken a lot of inspiration from the work we do at nao - our Cursor for data : giving the right data context to the agent, and then making sure that the agent helps you analyze the data without leaking it - thanks to privacy mode.
🧰 Step 1: Setup
First, let’s import all necessary packages
# Import packages
import json
import pandas as pd
from openai import OpenAI
from google.cloud import bigquery
from google.cloud.exceptions import BadRequest
Then, let’s set up our BigQuery and OpenAI config
# Set parameters
# BigQuery setup
project_id = ‘PROJECT_ID’
client = bigquery.Client(project=project_id)
# Max GB to run a query
max_gb=30
# Openai setup
api_key = ‘API_KEY’
base_url = ‘<https://api.openai.com/v1>’
default_headers = {’Authorization’: f’Bearer {api_key}’}
model_name = ‘gpt-5-2025-08-07’
⚙️ Step 2: Pre-prompt the Agent
The first step is to give our agent its system prompt.
This will tell the agent what its main goals are, and the rules it should always follow.
## Pre-prompting of agent
# System prompt
system_prompt = ‘’‘Your role is to translate requests to SQL queries for BigQuery.
IMPORTANT: You have access to tools to help you.
IMPORTANT BEHAVIOR RULES:
Always explain with one short sentence what you’re going to do before using any tools
Don’t just call tools without explanation.’‘’
You can also add some user rules if you want the agent to be configured differently depending on the user
# User rules
user_rules = ‘Use USING for joins - when possible. Put SQL keywords in uppercase.’
🔧 Step 3: Define tools
The execute_query() function does two things:
Dry Run: Check if the SQL is valid and estimate the cost - so that we don’t execute overly costly queries, and indicate to the LLM if the query written is right.
Run It: If it’s safe, fetch the data and return results.
First, we write the python function that will be executed programmatically.
## Define tools
# Declare python function
def execute_query(query):
print(’Query:’, query)
# Step 1: Dry run to validate query and check cost
try:
print(’⚙️ Performing dry run...’)
job_config = bigquery.QueryJobConfig(dry_run=True, use_query_cache=False)
dry_run_job = client.query(query, job_config=job_config)
# Calculate cost in GB
bytes_processed = dry_run_job.total_bytes_processed
gb_processed = bytes_processed / (1024 ** 3) # Convert bytes to GB
print(f’💰 Query cost: {gb_processed:.2f} GB’)
# Check if query is too expensive
if gb_processed > max_gb:
return {
‘success’: False,
‘error’: f’Query cost is {gb_processed:.2f} GB which is too costly (max: {max_gb} GB)’,
‘data’: None
}
print(’✅ Dry run successful, proceeding with execution...’)
except Exception as e:
print(’❌ Query failed, check the query syntax’)
return {
‘success’: False,
‘error’: f’Query validation failed: {str(e)}’,
‘data’: None,
}
# Step 2: Execute the actual query
try:
print(’🚀 Executing query...’)
job = client.query(query)
results = job.result()
# Convert results to list of dictionaries for easier handling
data = []
for row in results:
data.append(dict(row))
print(f’✅ Query executed successfully! Returned {len(data)} rows’)
# Print the preview in a dataframe
df = pd.DataFrame(data)
display(df)
return {
‘success’: True,
‘error’: None,
‘data’: data
}
except Exception as e:
return {
‘success’: False,
‘error’: f’Query execution failed: {str(e)}’,
‘data’: None
}
💡 This way of writing code, doing a dry run, and re-writing if the dry run fails is quite close to cascading. The whole concept is to let the LLM auto-fix its errors. We do similar system in nao to avoid executing queries that are doomed to fail.
Then, we need to describe the function for OpenAI to understand what the function does and how to call it:
# Describe function for OpenAI
openai_tools = [
{
“type”: “function”,
“function”: {
“name”: “execute_query”,
“description”: “Execute a SQL query on BigQuery. Returns the query results.”,
“parameters”: {
“type”: “object”,
“properties”: {
“query”: {
“type”: “string”,
“description”: “BigQuery SQL query to estimate the cost of.”
}
},
“required”: [”query”],
“additionalProperties”: False
},
“strict”: True
}
}
]
# Simple tool description - convert tool dict to string
tools_description = f”Available tools:\\n{json.dumps(openai_tools, indent=2)}”
Finally, we create a tool registry that links a function name to the corresponding python function:
# Tool registry to link tool names to functions
TOOL_REGISTRY = {
“execute_query”: execute_query,
}
🤖 Step 4: Build the Agent Loop
This is the part where we orchestrate the pre-prompting, the user messages, and then the assistant answers and tools execution.
You can see the agent as a thread of messages, with 4 types of messages:
System: rules given by the system prompt
User: messages sent to the agent by users
Assistant: messages returned by the LLM
Tool: results of executed tools
Here, we do a loop which:
Starts by sending system prompt + user prompt to the AI agent
Receives the agent messages + tool execution intentions
Executes tools
Sends back the result to the agent as a message
Etc. until no more tools need to be executed
Let’s start by the initial messages
# Create agent
def run_agent(user_prompt, context=’‘, privacy_mode=True):
# Concatenate all prompts
messages = [
{”role”: “system”, “content”: system_prompt + “\\n” + tools_description},
{”role”: “user”, “content”: user_rules},
{”role”: “user”, “content”: user_prompt + “\\n” + context}
]
Then we start the loop by getting a first answer from the agent, with some potential call execution intents
# Get response
llm_client = OpenAI(api_key=api_key, base_url=base_url, default_headers=default_headers)
running = True
while running:
response = llm_client.chat.completions.create(
messages=messages,
model=model_name,
tools=openai_tools,
parallel_tool_calls=False,
stream=False,
)
# Get message
message = response.choices[0].message
print(”🤖 Assistant:”, message.content)
We extract the list of tools to execute, and add assistant and tools messages to the stream of messages with the agent:
# Get tool calls list
tool_calls = []
if message.tool_calls:
# List tool to call
for tool_call in message.tool_calls:
tool_calls.append({
“name”: tool_call.function.name,
“args”: tool_call.function.arguments,
“id”: tool_call.id
})
# Add tool calls to messages
messages.append({
“role”: “assistant”,
“content”: message.content,
“tool_calls”: [
{
“id”: tc.id,
“type”: “function”,
“function”: {
“name”: tc.function.name,
“arguments”: tc.function.arguments
}
} for tc in message.tool_calls
]
})
else:
# Add assistant message to messages
messages.append({
“role”: “assistant”,
“content”: message.content
})
Then, we execute the tools programmatically
# Execute tool calls
for tool_call in tool_calls:
try:
print(f”🛠️ Calling: {tool_call[’name’]}”)
result = TOOL_REGISTRY[tool_call[”name”]](**json.loads(tool_call[”args”]))
if privacy_mode:
result = ‘Results hidden due to privacy mode’
# Send tool results back to LLM
messages.append({
“role”: “tool”,
“content”: json.dumps(result),
“tool_call_id”: tool_call[”id”]
})
except Exception as e:
print(f”❌ Error calling tool {tool_call[’name’]}: {e}”)
messages.append({
“role”: “tool”,
“content”: f”Error: {str(e)}”,
“tool_call_id”: tool_call[”id”]
})
Notice here that we have included a privacy mode - this is what we do at nao, our AI data editor, to make sure that the data content is not sent to the LLM unless the user allows for it. The security of your data should be first when playing with data & LLMs!
Finally, we stop the loop if no tools were executed.
# If tools were called, keep running
running = len(tool_calls) > 0
💡 Step 5: Ask a Real Question
Now it is time to use the agent!
Here I prompted it with this context and prompt:
# Launch a request to your agent
# Define if privacy mode is on or off (privacy mode = query results are not shared with the LLM)
privacy_mode = True
# Provide context
context = ‘’‘
Table: nao-dbt-demo.nao_corp.customers
Columns: customer_id, created_at
Table: nao-dbt-demo.nao_corp.retailers
Columns: retailer_id, created_at, cancelled_at
‘’‘
# Enter a user prompt
user_prompt = ‘’‘
How many clients do I have?
How many retailers do I have?
Answer the question in two distinct queries. and Execute one after the other.
‘’‘
Here is how I run the agent:
run_agent(user_prompt, context)
And got this result !
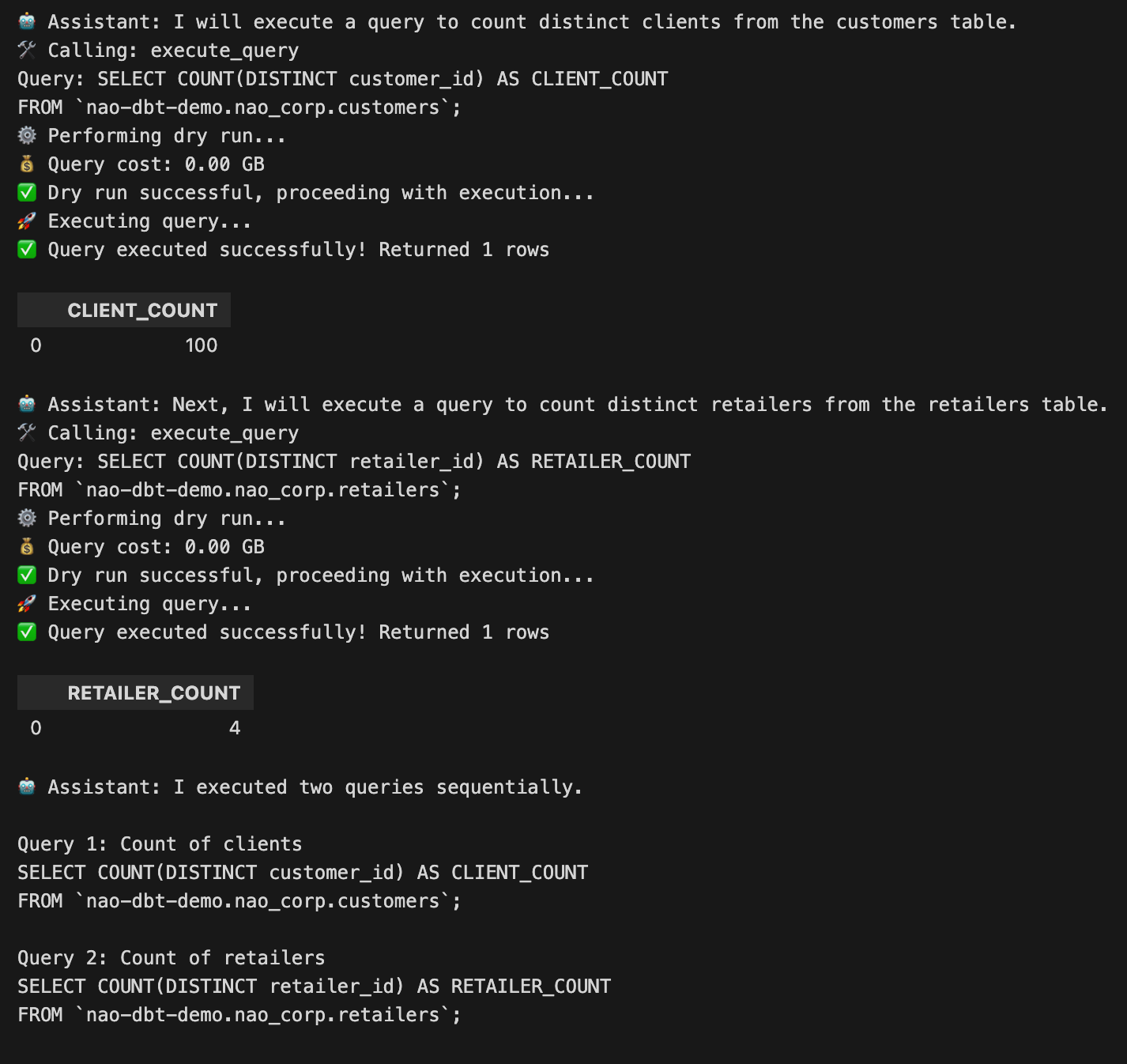
🐍 Full python script
The full Jupyter notebook is in our Git repo data-vibing-tools here:
simple AI analytics agent.ipynb
👣 Next steps
This example is a very simple agent to mainly understand the logic of the agent messages loop, and how tools happen in the flow of the agent.
I have many ideas on how to improve this agent, might implement it in later articles or even a GitHub repo:
How to programmatically pass the data context: with a tool or a RAG
Make it possible to send several messages to the agent while keeping the memory - probably with a Python class and a concept of Chat.
Add an MCP to the agent, to interact with other warehouses
Stream agent responses so that it’s faster - but tricky to do on a Jupyter notebook!
Any other ideas on what I should improve?
Let me know if this is helpful!