
How I improved my analytics agent reliability from 45% to 86%
#2 Context engineering study - from understanding your agent failures to tuning your context for better agent performance

In my last study, I tested 10 different context configurations on 40 unit tests and found that the best setup - file system + schema + sampling + rules.md - reached 45% reliability. Still better than the 17% I started with, but still too bad to put in business users hands.
So I kept going.
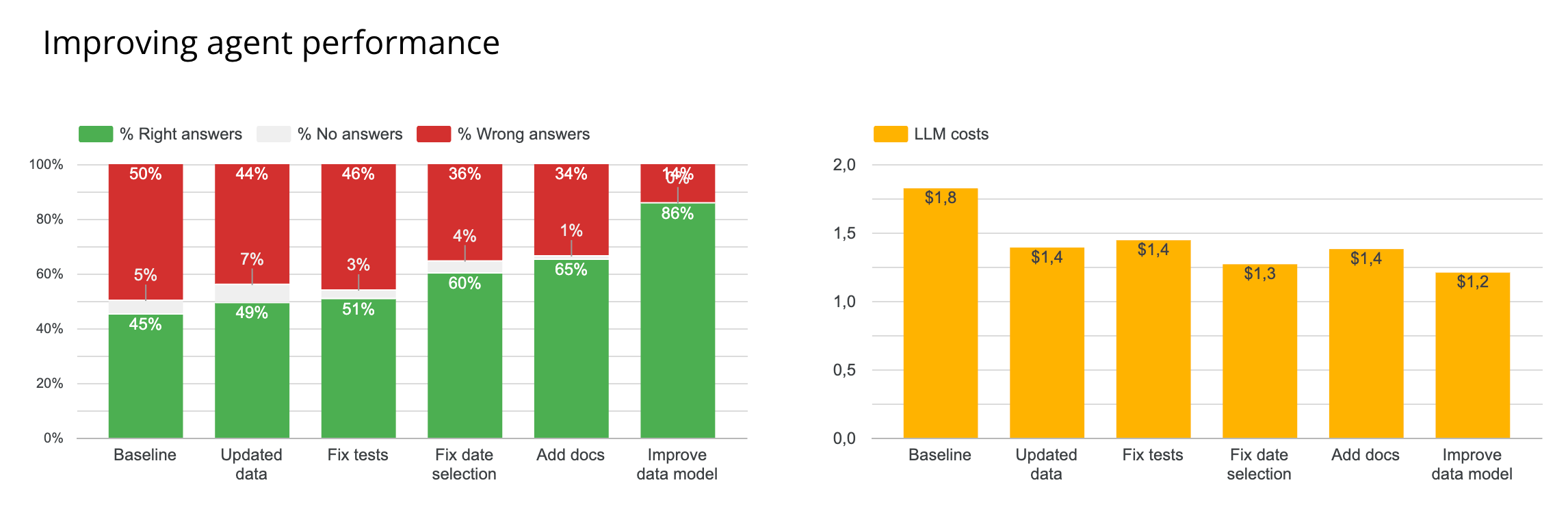
I started by dissecting my agent failures, and tuned the context accordingly to improve performance of the agent. The result: I went from 45% to 86% reliability, achieved through 4 concrete improvement steps: fix data model, add more documentation, add date selection rules and fix ambiguous tests.
👉🏻 Refresher of first context engineering results here:
First context engineering study - are semantic layers worth it?

Everyone has an opinion about what makes analytics agents work. “Semantic layers are the answer”. “Ontology is the key”. “Add data sampling”. “Build sub-agents”.
🔍 Diagnosing why my agent is failing
Before fixing anything, I started by understanding how the failures were spread out across tests:
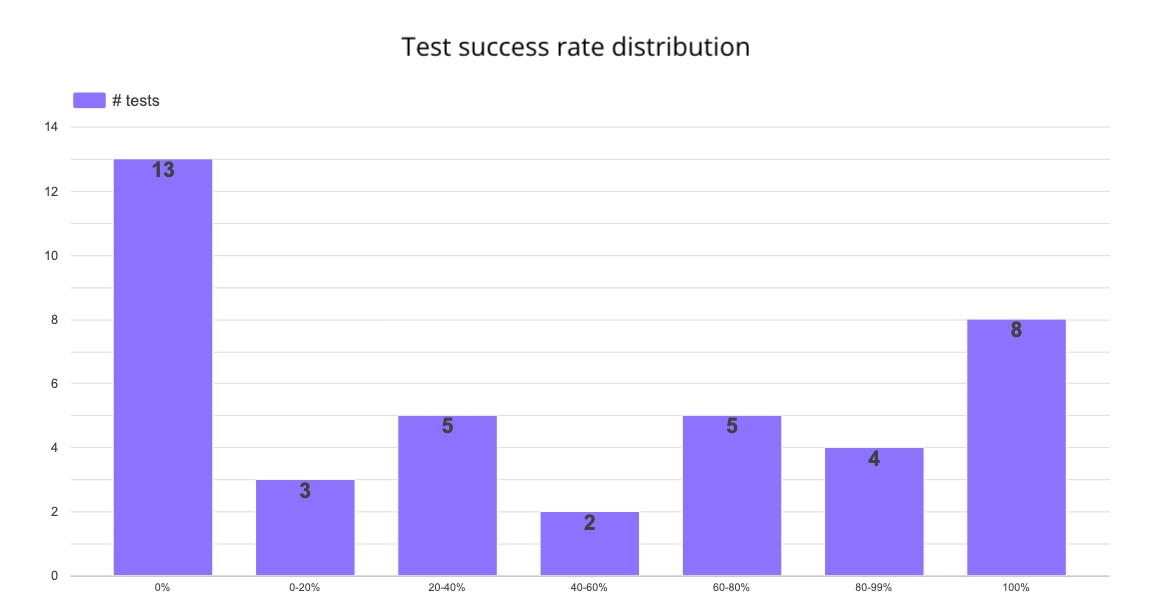
I looked at the failure rate for each of my 40 tests across the top-performing experiments. The distribution was skewed: 13 tests never got a right answer. 12 were correct more than 80% of the time. Everything in the middle was inconsistent.
That told me the problem wasn’t random hallucinations. Certain questions were systematically breaking the agent. So I took the 28 tests with less than 80% success and dug into each one.
For each failed test, I looked at the agentic loop: what mistake the agent did, what context it used, which assumptions it took.
As a recap, here is how I categorized each test on a failure reason:
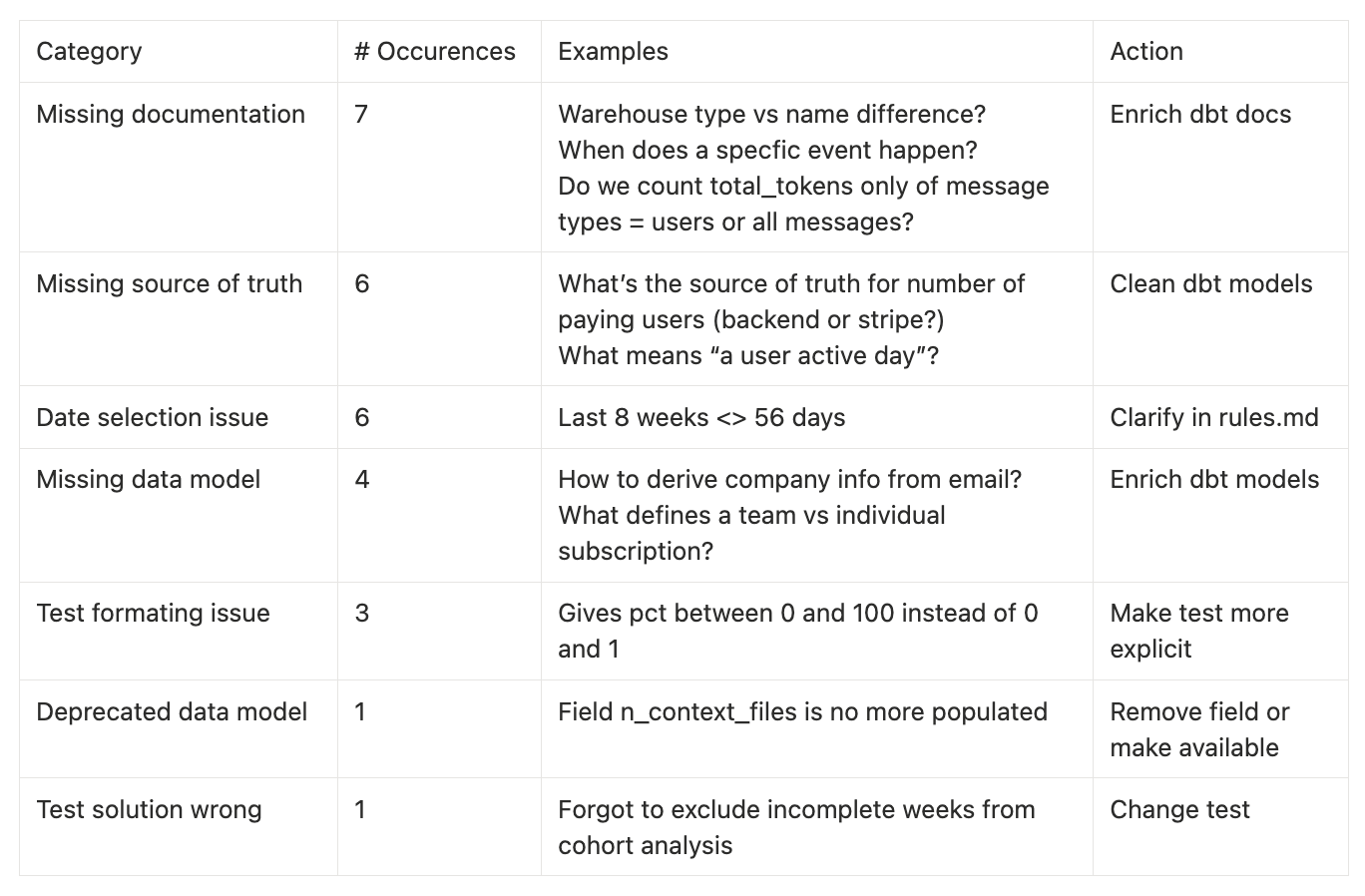
18 Data Model errors
Most errors are coming from my data model quality: it’s unclear, deprecated or incomplete. I’m asking the agent to guess new fields, or to decide which table is the source of truth for a metric. Or the data model is here and clear, but it’s not well documented.
6 Date selection errors
Many errors also came from the ambiguity of the date scope. Agent selecting last 56 weeks instead of last 8 weeks Monday to Sunday, etc. This might not give wrong numbers, but this is still not doing consistent numbers to the end users.
4 Test issues
Finally, some issues actually came from how the tests were built. One solution was actually wrong. And the others gave too few formatting indications to the agent (for ex how to format percentage)
Now that I knew what was going wrong, I could try to fix it.
The 4 steps to go from 45% to 86% reliability
For each category of error, I fixed the issue, and re-launched the tests step by step to evaluate which fixes had the most impact on reliability.
0️⃣ Re-establish the baseline 45 → 49%
Before improving anything, I re-ran the best context setup from the last study on current data to update our baseline. Since the test consists in comparing agent data output to source of truth output, if some edge cases were introduced in the last days, could make the agent fail.
Context
table schema + tables 10 rows preview + rules.md
Result
45 → 49% reliability
1️⃣ Fix tests errors 49 → 51%
Context changes
I fixed wrong tests & precised expected output for the agent to provide comparable outputs.
Results
49 → 51% reliability
2️⃣ Improve date selection rules 51% → 60%
Context changes
I improved the rules on date selection, making it clearer how to select ranges in weeks, dates, months. And what to do when no date frame was precised.
I already had rules on date selection, but it showed me that they were still too ambiguous. I had this rule:
"Last X weeks/days": Use >= date_trunc(current_date, ISOWEEK) - interval X weekBut when I traced the failures, I saw the agent was interpreting this in different ways. Sometimes it used TIMESTAMP() instead of DATE(). Sometimes it subtracted X weeks from today without aligning to ISO week boundaries. Sometimes it included the current (incomplete) week.
Each interpretation is not wrong, but they all give different numbers. And when a business user gets different figures on different days for “last 3 weeks,” they stop trusting the agent.
I rewrote the rules with explicit DO / DON’T examples:
#### "Last X Weeks" Queries
When users ask about "Last X weeks", always use **full ISO weeks** from Monday to Sunday,
and **exclude the current incomplete week** unless explicitly stated otherwise.
**DO** ✅:
```sql
date(created_at) >= DATE_TRUNC(current_date, isoweek) - interval 3 week
AND date(created_at) < DATE_TRUNC(current_date, isoweek)
```
**DON'T** ❌:
- Use timestamp functions: `created_at >= TIMESTAMP(DATE_SUB(CURRENT_DATE(), INTERVAL 3 WEEK))`
- Compute "today minus X weeks" (not full weeks): `created_at >= CURRENT_DATE - INTERVAL 3 WEEK`
- Convert weeks to days: 3 weeks is 3 full ISO weeks (Monday-Sunday), **NOT 21 days**
- Always convert timestamp fields to dates using `date()` functionResults
51 → 60% reliability
3️⃣ Add missing documentation 60 → 65%
Context changes
I added on dbt docs the definitions that were missing + added the most important ones in my rules.md
Results
60 → 65% reliability
4️⃣ Improve the data model 65% → 86%
Context changes
I added missing fields - that I was asking the agent to guess: booleans “has this user done this” where info was nested in events values, computed fields etc.
I clarified source of truth for each metric. For several metrics - number of paying users, number of active repositories - there were multiple possible source tables. I also realised some had several definitions: paying users could mean “paid licenses” or “users with a paid license” (which can be different if someone bought a license but never attributed it to a user) - so I split the metric in two.
I added a “metrics source of truth” section in rules.md
### Metric Source of Truth (CRITICAL) **For each key metric, always use the following source-of-truth table:** - **MRR / New MRR / Churned MRR / Churn Rate** → `fct_stripe_mrr` - All recurring revenue and churn metrics must come from `fct_stripe_mrr`. etc.I added rules to batter handle questions with ambiguity:
### "Our users" definition rules (CRITICAL) When a question mentions **"our users"** without a precise definition, the agent **must infer the right definition from context** and **always state explicitly which definition is being used in the answer**. - **Signed-up users (default)**: - Use when the question is general (e.g. "How many users do we have?", "What share of our users…") and **does not mention activity, payments, or licenses**. - **Definition**: All users in `dim_users` (`COUNT(DISTINCT user_id)`). - **Active users**: - Use when the question is about **usage, engagement, or activity over a time period** (e.g. "our users last week", "users who used feature X this month"). - **Definition**: Users with activity in the requested time window from `fct_users_activity_daily` or `fct_users_activity_weekly` (e.g. `n_active_users > 0` or `n_active_days > 0`). etc. In every answer that uses a user-based metric, **explicitly describe which user definition you chose and why**
Results
65 → 86% reliability
Quick note on the remaining 14% errors
The remaining 14% errors aren’t really wrong answer. They’re interpretation decisions, that could be done right with back-and-force with the user. For ex: “% of users with more than one warehouse” - out of all users, or out of users with at least one warehouse?
Getting from 86% to 100% on my test test set would mean overfitting to my specific expected SQL. I’d rather stop here and expand to real production questions.
🏆 Key context engineering learnings
If we recap all the steps, this is how each step improved the agent:
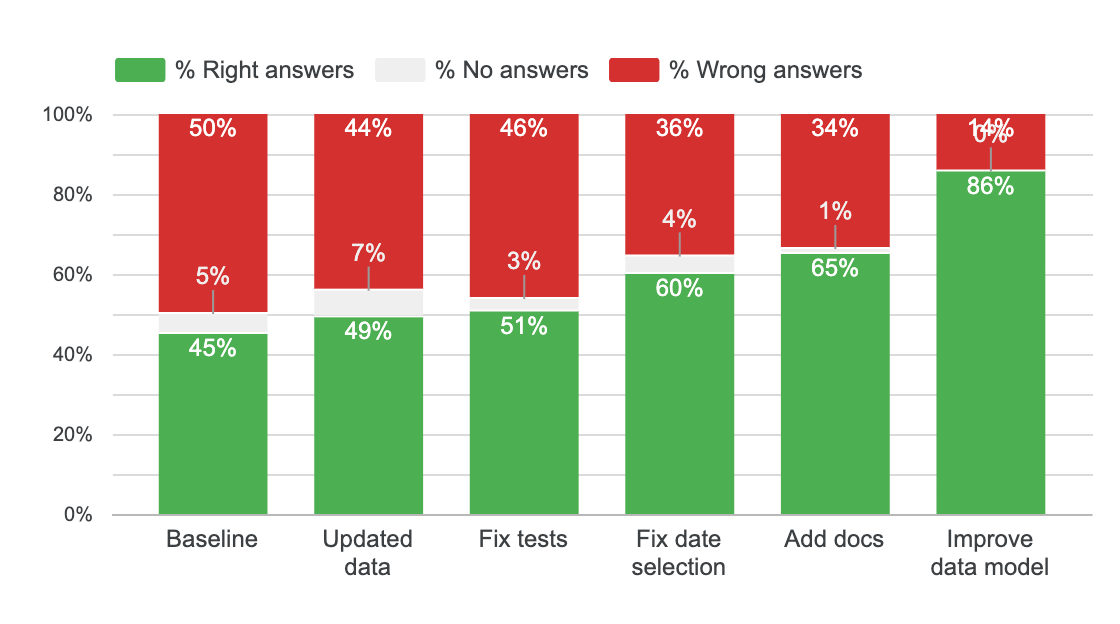
As you can see, improved data modeling had the most impact on agent reliability. So I guess… Context engineering is mostly data engineering.
I’ll sum up this article in 5 key learnings to improve your analytics agent:
Clean your data model until no ambiguity is left: if the agent doesn’t know which table to pick, you probably don’t either. Each point of failure of your agent helps you identify and fix data model ambiguity
Don’t make your agent guess: we used to avoid building 100+ fields in tables for human readability. Agents are different. They’ll be better at finding the exact field they need in 100 ones rather than creating it from 10 existing clear fields. So let’s create all these fields.
Remove any instability factors: date selection principles, source of truth table selection → they don’t create wrong answers, but they create instability for your end users. And instability will break their trust.
Anticipate users imprecision: in your rules, help the agent infer from context what vague terms mean - or at least ask follow-up questions. “Our users” means what in which case? “Currently” means which time scope? Etc.
Don’t overthink context format: every data team speaks about “semantic layers”, skills, MCPs etc. etc. Here, I reached 86% reliability with just .md files of metadata, and rules. I think we should push as much as we can with simple setups like this before urging to more complex ones.
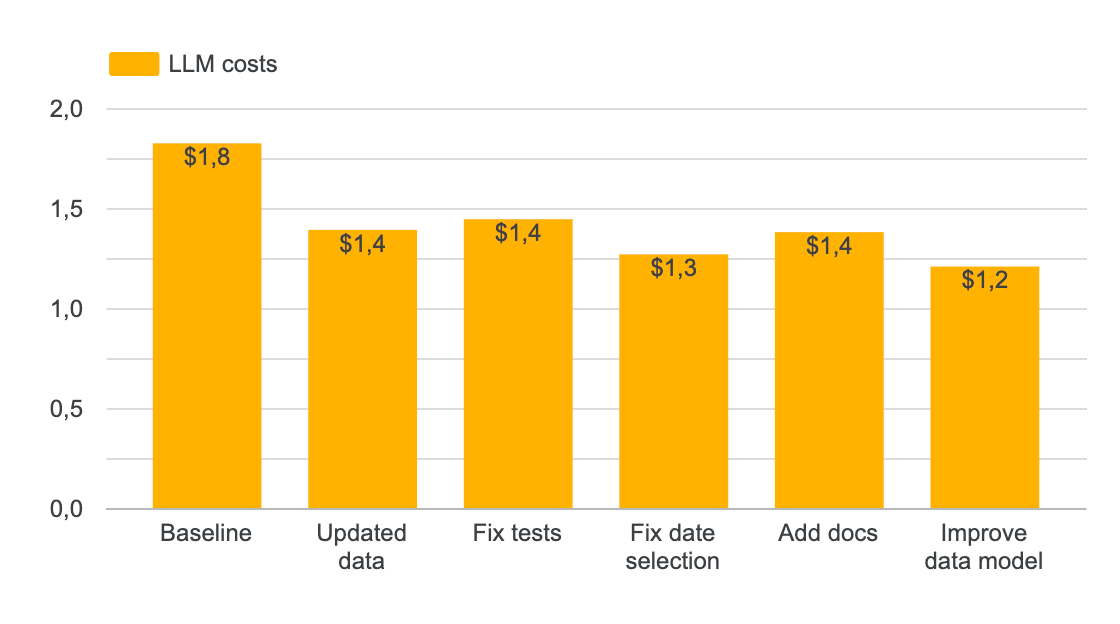
I didn’t speak so much about the other KPIs here, but I also saw a decrease in terms of costs. Less ambiguity = shorter agentic loops = cheaper runs.
⛹️ What’s next for you
Same caveat as last time: don’t trust my results. Run your own and share them.
You can start context engineering with nao in 5 minutes - check out our repo and our quickstart guide.
You just have to:
nao init - set up your context repo
Write a few unit tests (question + expected SQL in YAML)
Run your baseline evaluation against your current context
Categorize the failures: data issue, doc issue, test issue, or model issue?
Fix one category at a time. Re-run between steps.
→ Github repo | Docs
🛸 What’s next for me
I’m not going to keep iterating on these 40 tests. Instead:
Integrate real-life questions failures - next step is to monitor our internal chats, and keep learning on failures for this one to improve context. nao is releasing Chat Replay soon, which will let me monitor real questions asked on our internal agent. That’s a much more honest signal than a static test set I designed myself.
Make the semantic layer work - I’ve set it aside because only 16% of tests returned any answer with the dbt MCP setup. But I think more than 30 of my 40 tests could be answered by a semantic layer. I want to find the setup that makes this work.
Untangle my rules.md spagetthi - Right now my agent heavily relies on my rules.md, but I don’t think this will be scalable. I want to keep the most general rules in it, while keeping more specific context in my file system context.
Optimize cost without sacrificing reliability - I want to understand which pieces of context are most expensive in tokens, and trim accordingly.
Scale to more tables - I currently have 12 tables in my silver layer. Our activity has grown and I now have 21. I want to understand how reliability evolves as the schema expands, and our business grows more complex with several products.
Thank you for following up to here on this long article! Now I would love to learn from your own experiments. What did you find? What failure categories showed up in your data? I’m curious - reply or drop it in the comments.
I noticed that after you fixed tests, all 3 other improvements dramatically increased your accuracy. I've always thought of tests as something that enables/accelerates change.