
Data teams should become context teams
Context engineering = data governance + data engineering + data science.

Remember when your company connected their BI tool directly into the production database? Figures were always wrong. Nobody trusted the dashboards - so we built data stacks to fix that.
AI agents of today are the equivalent of BI tools plugged to production DB. Every company now has internal AI agents, plugged on raw context sources: drives, notions, mails. It kind of works, but you can’t fully trust the answers.
Context engineering is about creating sources of truth for all company knowledge, in a reliable and efficient way. And that’s exactly what data teams have been doing for data for years.
Context engineering needs the core skills that data teams have:
Context Engineering = data governance + data engineering + data sciences
Context engineering needs governance to define context source of truths
Context engineering needs engineering to ingest and consolidate them
Context engineering needs sciences to measure and improve AI reliability
What is context engineering?
Context engineering aims at creating the optimal context for AI agents.
What’s an optimal context for an agent?
Answer rate: the percentage of questions the agent can actually answer
Accuracy: the percentage of answers that are correct
Cost: LLM costs incurred by the agent
Speed: how fast the agent responds
What are the trade-offs to optimize for?
Too little context → wrong or no answers.
The agent doesn’t know enough. It hallucinates, misses nuance, or gives up entirely.Too much context → expensive and confused.
Input tokens can make the LLM bill escalate very fast (1 Million tokens in Claude Opus 4.5 is $5) . A context-heavy call can easily send 50–100K tokens per query, which would be ~50c. And beyond cost, irrelevant context dilutes the signal — the model gets confused by noise.
How can you engineer context?
Choose which sources to include and which to exclude.
Clarify which content is the source of truth on one topic (right definition, freshest source). Sometimes you might discover yourself are not clear in the first place.
Create new context where it doesn’t exist yet.
Format context so the model can parse it efficiently: make it more modular, well structured.
In short, context engineering follows the same principles as data engineering: measure, iterate, optimize. Track your agent’s performance. Identify causes of failures. Add missing context. Test improvements. Repeat.
Context governance: context source of truth is the new data source of truth
We have the same needs of context governance as we had with data governance.
We needed data governance because without it, “revenue” meant three different things depending on who you asked. The marketing team counted gross bookings. Finance counted net ARR. The product team counted active subscriptions. No metric layer, no canonical definition - so every dashboard told a different story.
Today, we need context governance because company knowledge has the exact same problem. Ask “what’s our refund policy?” and the answer depends on which doc the agent finds first - the outdated Notion, the latest Zendesk answer, or the slack message from legal last quarter. And sometimes, nobody has really thought about what’s the real answer to this.
Many data people have known scary times where they arrived at a company where the BI was plugged to production database. All the data was here, no two figures looked the same, everything was slow and painful. Today, we do exactly the same by plugging AI to our whole company knowledge.

We all know that company knowledge is full of inaccuracies, obsolete elements, contradictions. So plugging an agent directly to this mess doesn’t seem the best thing to do.
What we need is a context laye: a single, governed, versioned source of truth for company knowledge. The clear answer to every question the agent might face. And we need infrastructure to build and maintain it.
Context engineering: the context stack is a data stack
To have data sources of truth, we have built the data stack.
For context sources of truth, we need a context stack.
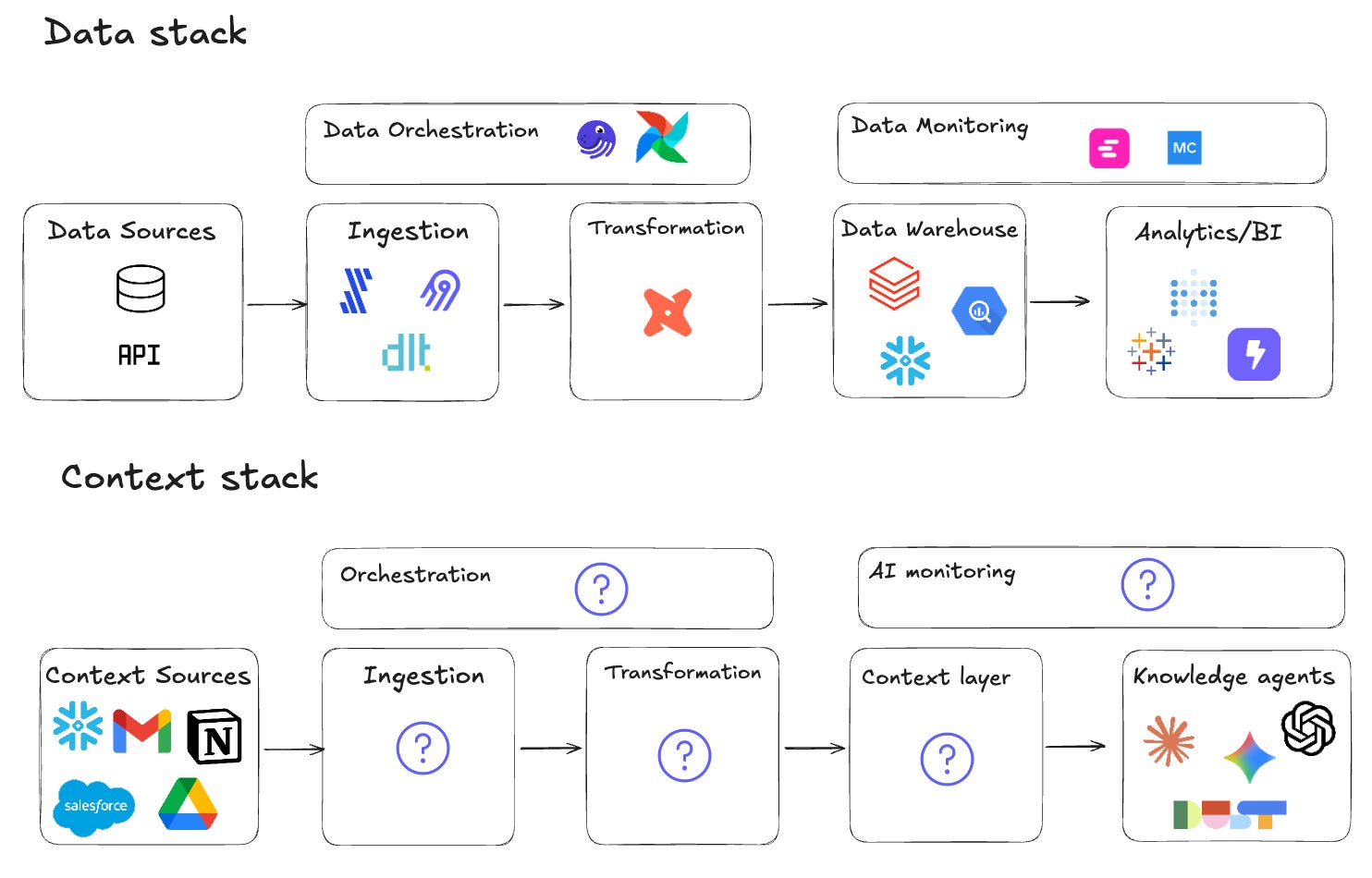
The situation today is the same in data 10 years ago: we have sources, we have consumption tools. But we don’t have the middle stack, the context ETL layer.
We need:
Ingestion tools to automatically pull context sources
Transformation tools to pick the context source of truth
Context layer to be the source of truth of our company knowledge
Orchestration to have fresh context
AI monitoring to measure and track performance of our context in AI agents
Some data teams have already started building pieces of this in-house. I’ve seen teams write scripts to pull schema metadata and profiling stats from the warehouse, sync documentation from their data catalog, or curate vetted queries from the BI tool into markdown files. It works — but it’s a lot of scripts and maintenance.
Monitoring is further behind. Most analytics agent tools don’t support evaluation frameworks yet, so there’s no easy way to build unit tests that verify your context still produces the right answers after a change.
Once we have the governance and the stack, we need to use our data sciences techniques to iterate and improve our context.
Context sciences: fine-tuning your context like ML model parameters
In ML, you define a success metric (accuracy, etc.), and have a train test set of labeled data. Then you tune parameters, features, train sets. You measure performance after each change until you find the optimum.
In context engineering, it should be the same loop. You define your success metrics (reliability, costs, etc.). Your parameters are the context sources of truth, context formatting, tools. You can create a unit tests sets of prompts / expected answers. You change the context, re-run your test prompts, measure the impact, keep what works.
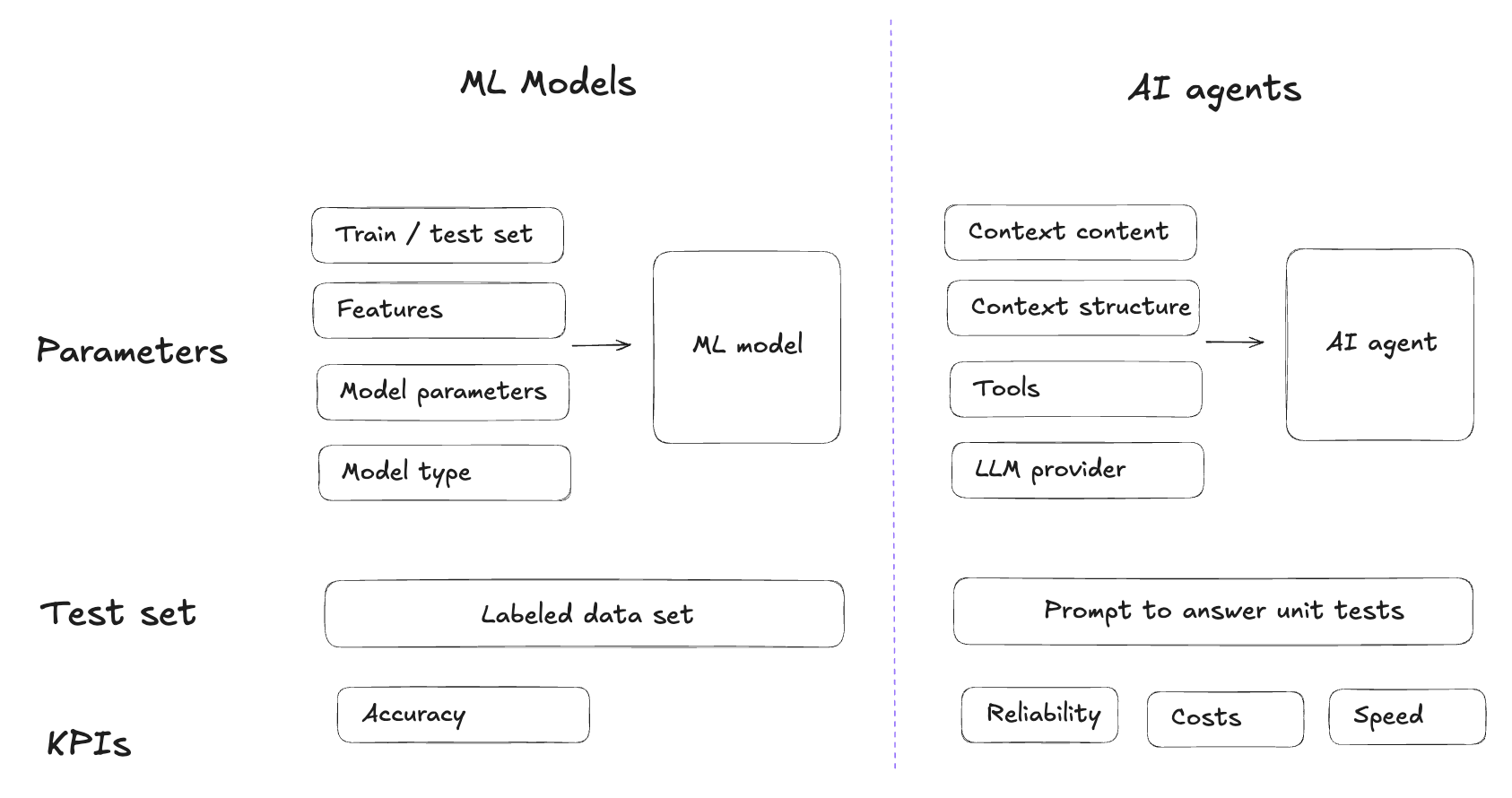
The extra thing to crack though is how to measure your metrics → costs, speed are easy to measure but you need more tailored tools to measure agent reliability: Check the file sources used? An exact match? LLM as a judge?
To do this, you need to build yourself an evaluation framework. Define the KPIs you’re going to track - what is agent success, how to measure it, what other parameters are important (costs, speed, etc.). Then build unit tests and fine tune your context by measuring performance on different sets of context.
How to start transition now
As you’ve seen, the context stack is not there yet. We are still missing tools to openly curate and improve our context.
I think a first step for data teams would be to show that they master context engineering on their scope first: can you actually make context for your analytics agent work?
As I explored in my previous articles of analytics agents benchmarks, on the shelf solutions are not working and are context black boxes. If data teams invest in context engineering their own analytics agents, I’m sure they can demonstrate it works better than off the shelf agents.
Two setups can already works for getting into context engineering:
File-system AI agents (Cursor, Claude Code, Cowork, Codex, nao)
These tools read context directly from files you control. You can see exactly what the agent knows, change it by editing a file, and measure the impact immediately. Plus, you can build an evaluation framework on top since everything is accessible with code.
In-house agents
If you’ve built your own agent, you control the full context pipeline: which piece of context you want to add, and how you’re going to evaluate your agent. Create a set of prompts unit tests, then start to play them on different context scenarios.
We’ve been thinking a lot about this at nao. We want to bring the missing ETL + monitoring founding brick to the context engineering for data analytics.
We’re actually launching this tomorrow - stay tuned!
Happy to hear your thoughts on this - do you want to get into context engineering as a data team?
Do you think context engineering will be a fractured as the “Data Stack”?