

AI is changing work. What about data? 🤔
Everyone talks about AI changing work, from GenAI to AI agents. But how can I change my data team with them?
We already see data stack tools adding AI features: chat with your data in your BI, text to SQL in your documentation tool, auto-complete features in your data warehouse console.
But our friends of software engineering use GenAI differently: directly where they produce code, with the AI code editor.
What's an AI code editor? 🛠️
They are 2 types of AI agents for code editors:
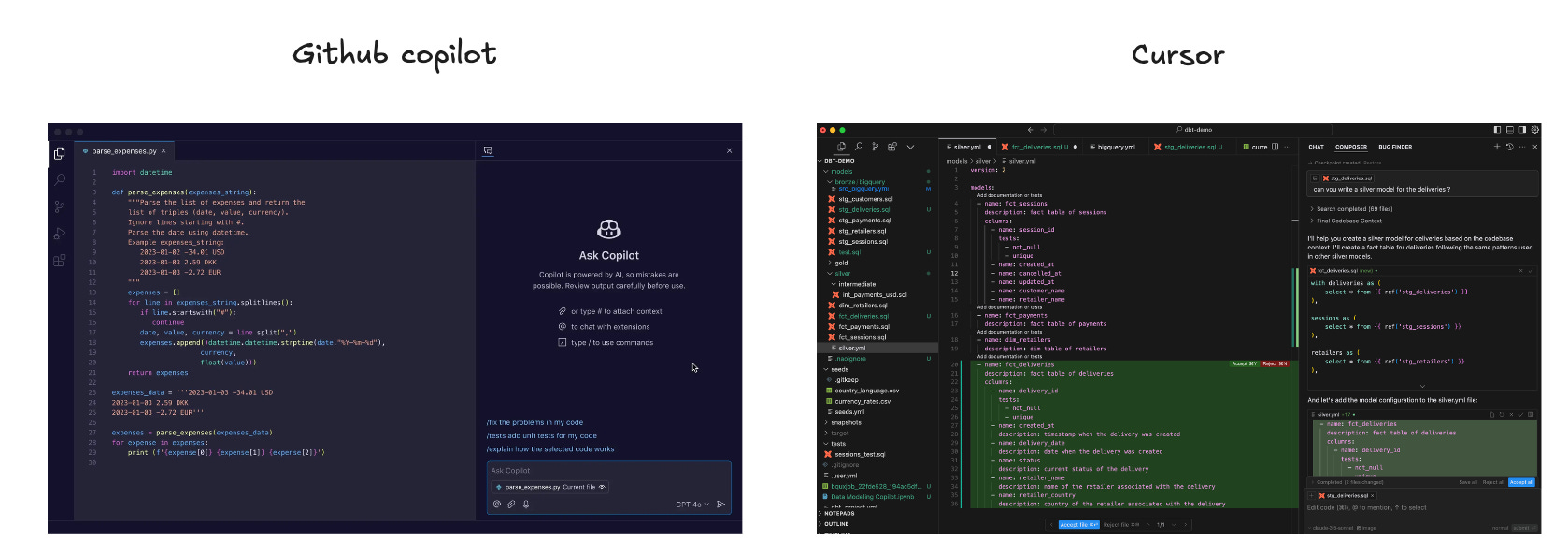
AI-powered extensions like GitHub Copilot for VS Code
Native AI code editors like Cursor or Windsurf
Extensions look great because they are already in your existing tools: Github, VS Code. But native AI editors are built with AI-first features. They provide deeper integration, better context understanding, and often more advanced assistance.
3x more productivity ⚡️
Software engineers claim they have at least multiplied their productivity by 3 using AI code editors. At STATION F, I've heard things like:
"I code with tab now"
"I don't even look at my code errors, I just ask the copilot to fix them"
Why I think this applies to data teams 📊
My experiences have brought me one conviction:
Key success factor of your data team is how you prepare the data.
May it be fore a data sciences model, your BI tool or analytics.
And where do you prepare the data? In your code editor.

9 data teams feedback on using AI code editors 💬
I've talked to 70 fellow heads of data, and only 9 were using AI code editors.
Many were not convinced by GitHub Copilot but were blown away by Cursor.
For now, they mainly use AI code editors for:
Data modeling (working with dbt) ⚙️
Data science development in Python 🐍
Their main feedbacks:
✅ They bring amazing speed.
Data teams increase their productivity: "Cursor makes me gain 60% of dev time", "80% of my code is written with cmd+K"
Low added-value tasks take minutes instead of hours: “The autocomplete is crazy. I don’t even have to ask and it writes something relevant and clean. It helps me with writing documentation and kick-start my data modeling.”
Repetitive tasks are automated: "If I do the same transformation on 20 files, it will get it and apply it to all."
❌ AI code editors are not fully adapted to data work yet.
They invent table & column names that don’t exist, because they don't have the data warehouse context: “I still have to always check the suggestions. Sometimes it invents field names”
They don’t understand some specific data frameworks like dbt lineage: "If I change a table in my data model, it won't notice that I broke tables downstream"
They can't test the code written on your actual data, leading to errors: "I still need to test the values I obtain after my code changes"
AI code editors are already great, but they still have blind spots for data teams.
(🤫 I've heard a company called nao Labs is working on solving these issues...)
So is it worth paying for? 💰
I want my data team to produce impact, not code.
So if they can go faster on writing code, to spend more time on producing insights & data products, I will pay for it.
Now we need to measure how much productivity data team actually gain with these tools, because they are still not 100% adapted to them. But AI code editors are easy to test: they are freemiums. You can test them for 2 weeks free, and see how they improve your work!
I'll keep you posted on my findings on the subject. Send some feedbacks if you tested AI code editors for your data team 🏎
Great read, curious to see how this pans out for data engineers. Like you mentioned in your first cons, hallucinations in data must be a big no no. But I do believe as LLM providers become better, the people that build specific AI agents for that specific use case, will most definitely win. 🏆